不安全的HashMap
总所周知,HashMap是非线程安全的,体现在rehash时的死循环,使用迭代器时的fast-fail和多线程环境下put操作出现丢失数据等。
虽然JDK也提供了一个安全版本的HashMap:Collections.SynchronizedMap,但因为其使用的是全局锁,并发性能较差。
因此,juc包下提供了线程安全且锁粒度较小的ConcurrentHashMap。
ConcurrentHashMap的结构与实现原理
ConcurrentHashMap在JDK1.7和JDK1.8中有者不同的实现。
1.7下的ConcurrentHashMap
JDK1.7下的ConcurrentHashMap使用分段锁来提高并发访问效率,每把锁锁容器内的一部分数据,当多线程访问容器里不同数据段的数据时,就不会出现锁竞争。
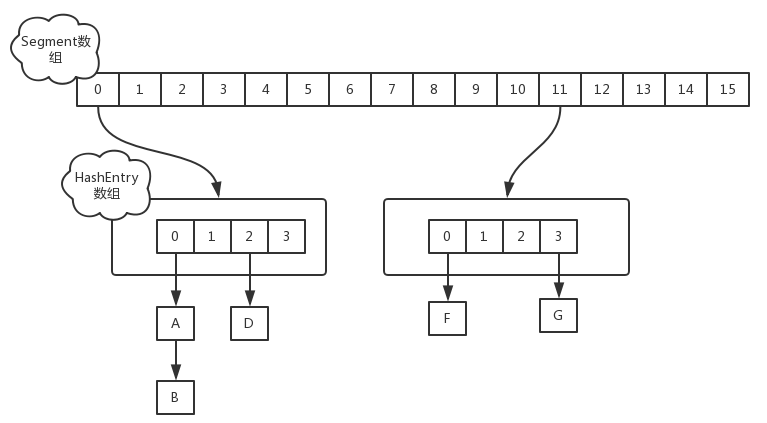
1.7中ConcurrentHashMap是由Segment数组和HashEntry数组组成。Segment是一种可重入锁ReentrantLock,扮演锁的角色;HashEntry则用于存储键值对。一个ConcurrentHashMap中包含一个Segment数组。Segment的结构和HashMap类似,都是数组+链表结构。一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,每个Segment元素锁着对应的HashEntry数组里的元素。想要修改HashEntry数组中的元素时,必须先获得对应的Segment锁。
初始化
ConcurrentHashMap初始化时,计算出Segment数组的大小ssize和每个Segment中HashEntry数组的大小cap,并初始化Segment数组的第一个元素;其中ssize大小为2的幂次方,默认为16,cap大小是2的幂次方或1,最终结果根据根据初始化容量initialCapacity进行计算。
定位Segment
ConcurrentHashMap使用分段锁来保护不同段的数据,那么在插入、获取数据的时候,必须先定位到Segment。
ConcurrentHashMap首先会对key的hashCode()使用hash()方法进行再散列,目的是减少哈希冲突,使元素能够均匀的分布在不同的Segment上。
get操作
get操作只需要将再散列得到的散列值通过散列运算定位到具体的Segment上,再通过一次Hash定位到具体的元素上。
整个get操作都不需要加锁,除非读到的是空值才需要加锁重读。由于 HashEntry 中的 value 属性是用 volatile 关键词修饰的,保证了内存可见性,所以每次获取时都是最新值。
定位HashEntry和定位Segment的算法都是数组长度减一和哈希值相与,但定位Segment使用的是元素的hashCode通过再散列后的散列值的高位,而定位HashEntry使用的是再散列后的值。这样是为了避免两次散列后的值一样,没有同时在Segment和HashEntry中散列开。
put操作
put操作是写操作,虽然HashEntry中的value用了volatile修饰,但并不能保证原子性,必须要加锁。
put操作首先定位到Segment,然后定位插入位置,执行插入操作。插入分为两步:
判断是否需要扩容
插入元素前会判断Segment里的HashEntry数组是否超过容量,如果超过阈值,则对数组进行扩容。
扩容过程
扩容时,首先创建一个容量是原来两倍的数组,将原数组中的元素再散列后插入到新数组中。
ConcurrentHashMap不会对整个容器进行扩容,只会对某个Segment进行扩容。
size操作
size操作需要遍历所有的Segment才能计算出整个容器的大小,最简单的方案是锁住整个ConcurrentHashMap,但这样十分低效。
ConcurrentHashMap的做法是先尝试两次通过不锁住Segment的方式来统计各个Segment的大小,如果统计的时候容器的count发生了变化,再采用加锁的方式统计Segment的大小。每个Segment都通过变量modCount来记录修改次数,比较size前后modCount是否发生变化就可以得知容器的大小是否发生变化。如果两次的modCount都相等,则说明size()期间无更新操作,可直接作为结果返回。
1.8下的ConcurrentHashMap
1.8的ConcurrentHashMap取消了分段锁设计,而是采用CAS+synchronized来保证线程安全。
数据结构和HashMap类似,都是数组+链表/红黑树。
定位
Java 8的ConcurrentHashMap同样是通过Key的哈希值与数组长度取模确定该Key在数组中的索引。同样为了避免不太好的Key的hashCode设计,它重新定义了哈希方法计算得到Key的最终哈希值。
get操作
同1.7,get操作也不需要加锁。
由于数组被volatile关键字修饰,因此不用担心数组的可见性问题。同时每个元素是一个Node实例(Java 7中每个元素是一个HashEntry),它的Key值和hash值都由final修饰,不可变更,无须关心它们被修改后的可见性问题。而其Value及对下一个元素的引用由volatile修饰,可见性也有保障。
1 | static class Node<K,V> implements Map.Entry<K,V> { |
put操作
当执行put操作时,先根据key的哈希值在Node数组中找到对应的位置。
- 如果相应位置的Node还未初始化,则通过CAS插入相应的数据;
- 如果Key对应的数组元素(也即链表表头或者树的根元素)不为null,则对该元素使用synchronized关键字申请锁,然后进行操作。
- 如果该put操作使得当前链表长度超过一定阈值,则将该链表转换为树,从而提高寻址效率。
size操作
1.8中使用一个volatile类型的变量baseCount记录元素的个数,当插入新数据或则删除数据时,会通过addCount()方法更新baseCount。