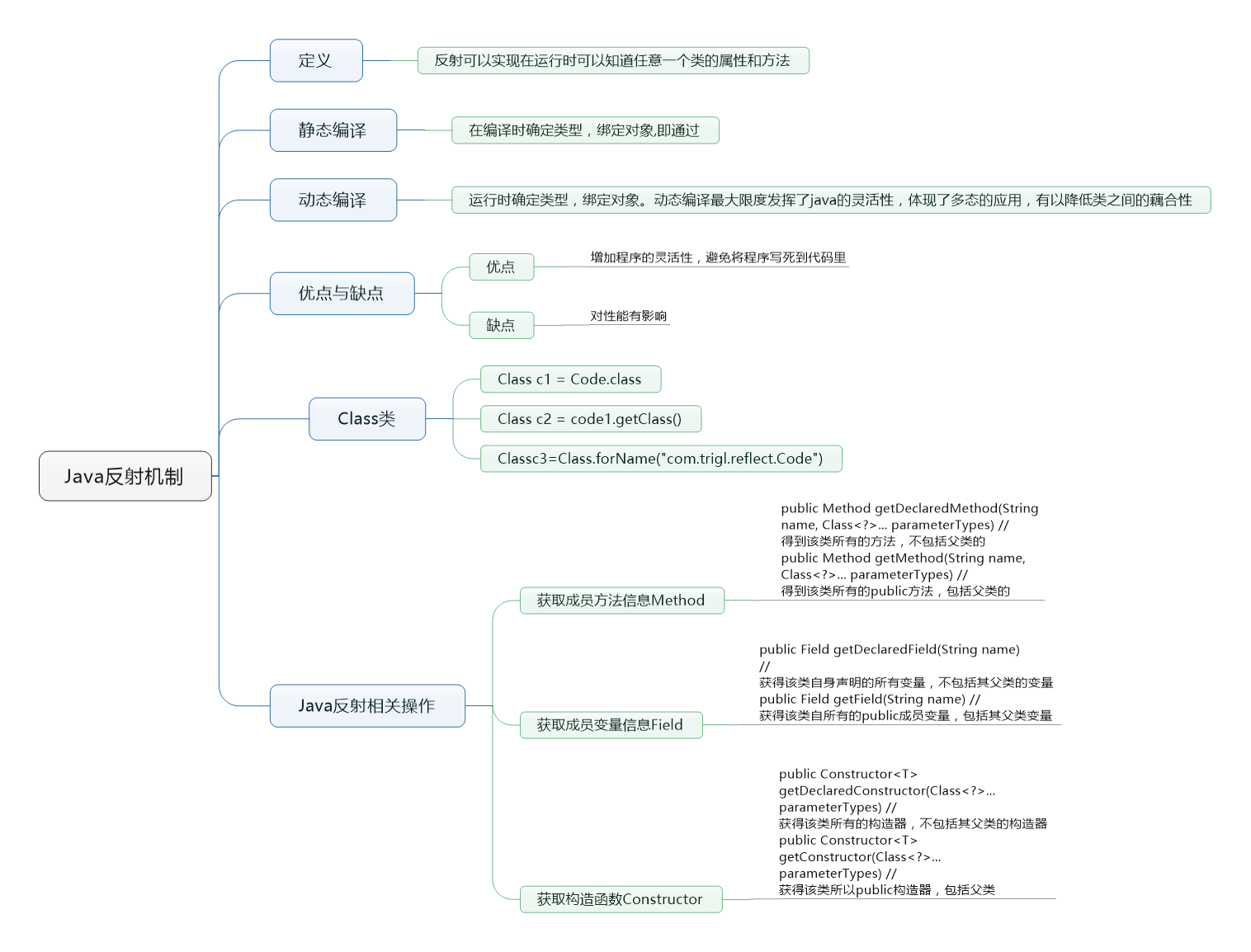
Java反射
Java 反射机制在程序运行时,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性。这种 动态的获取信息 以及 动态调用对象的方法 的功能称为 Java 的反射机制。
反射机制很重要的一点就是“运行时”,其使得我们可以在程序运行时加载、探索以及使用编译期间完全未知的
.class文件。换句话说,Java 程序可以加载一个运行时才得知名称的.class文件,然后获悉其完整构造,并生成其对象实体、或对其 fields(变量)设值、或调用其 methods(方法)。
反射可以实现在运行时知道一个类的属性和方法。